Sounds
& Seriation

Investigate the effects of various sound types on memory and assess if meaningful speech has a distinctive impact
Type
Human Performance Quantitative Research
Time
Dec 2023
Role
Data Analysis,
Poster Design
Tools
SPSS, Word, Figma
Team
Ahmed Wissem Chiheb, Hanlin Wang, Haohui Gong, Leonard Cheong, Zhengri Han
Introduction
In various settings, individuals routinely engage in performing tasks amidst different sounds. For example, centering on the academic context, students study in a variety of environments with different sound conditions such as music in the ears, or in a public place with spoken conversations in the background. The study of the interplay between background sound and performance is commonly known as the Irrelevant Sound Effect (ISE). Amongst the many aspects of this highly studied phenomenon, our group was tasked to looking into to primary questions:
1. Does irrelevant sound affect memory?
2. Is meaningful speech special or will any sound affect memory (like music?)
A literature review suggests two key conditions for the occurrence of ISE. Firstly, the sound must exhibit significant acoustical variation over time. Secondly, tasks susceptible to ISE involve seriation, where information retrieval follows a specific order through rehearsal, like serial recall. The resulting impairment arises from a conflict in processing two simultaneous sources of order information: intentional seriation for memory retention and preattentive processing of acoustically-variable items in irrelevant sound (Perham & Vizard, 2010).
Considering these questions, one anticipates that irrelevant sound affects memory, especially in serial recall, and that speech meaning is secondary to the acoustical variation of other sounds. The ensuing study aims to verify these expectations.
Method
Participants
Students from the University of Nottingham enrolled in the Human Performance module, engaged in this study as part of their exploration into the Irrelevant Sound Effect (ISE). There were no known hearing or vision impairments. There were no known hearing or vision impairments. All students spoke English, either natively or as a second language.
Design
A repeated measures design was employed with five independent sound variables - silence, music, speech, backward speech, and numbers. The dependent variable was the number of items recalled in their correct serial position (out of 8).
Materials
Five distinct sound files for each sound type was distributed to students. Within each sound file, students memorized 10 random sequences of 8 digits (1-8), with each digit being shown for 1 second. Following the display of each digit, the corresponding sound type played for10s, after which students recorded the memorized sequence on an Excel file. For the sound types that our group was focused on, the music played were random sections of Mozart’s Eine Kleine Nachtmusik and the speech played was of a female voice reading Harvard Sentences.
Procedure
Perhaps due to the large number of participants, the study was conducted in an unsupervised manner, allowing students to participate at their convenience. Participants were instructed to wear headphones, adjust the volume to their comfort, and were scored based on the accuracy of recalling numbers in the exact sequence position. Completed studies were submitted to Professor Robert Houghton, who curated the datasets. A random subset of data from 70 students was provided for our analysis.
Removal of outliers and bad data
Bearing in mind the unsupervised nature of the test, the team was mindful to look out for outliers and potential bad data that could misrepresent the distribution. After generating descriptives with SPSS, three participants exhibited scores beyond 1.5 times the Interquartile Range for silence and speech sound types. Data from these outliers were excluded. Additionally, the incomplete scores of a participant in the silence test were removed. Subsequently, the analysis focused on the cleaned data of the remaining 66 participants.
As this involved a comparison with one independent variable of three levels within subjects, the chosen test was a one-way ANOVA. To conduct the test, we ensured that the data were normally distributed and confirmed homogeneity of variance. Descriptives for the new dataset indicated a Z skew for all sound types was less than ±1.96. We further verified homogeneity of variance across sound types by confirming that Fmax < Fcrit.

Results
Participants demonstrated the typical serial recall curves as shown in previous studies, where performance tended to be better for numbers shown earlier and later on.

A one-way Anova within subjects using the General Linear Model revealed that there was a significant effect of sound type on serial recall. F(3, 66) = 4.83, p < 0.05.
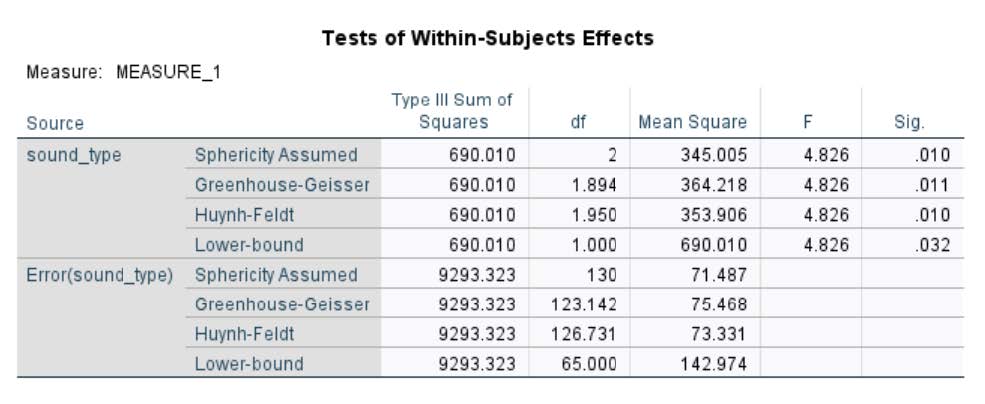
A post-hoc comparison of means showed that:
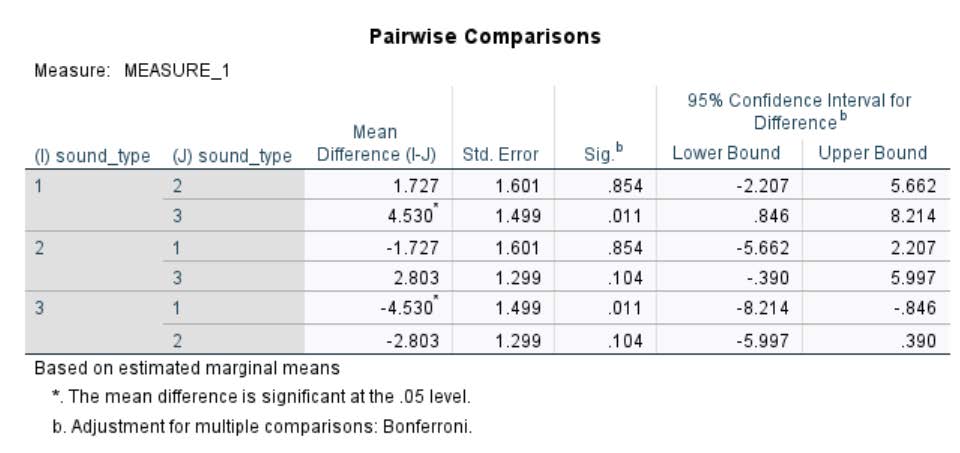
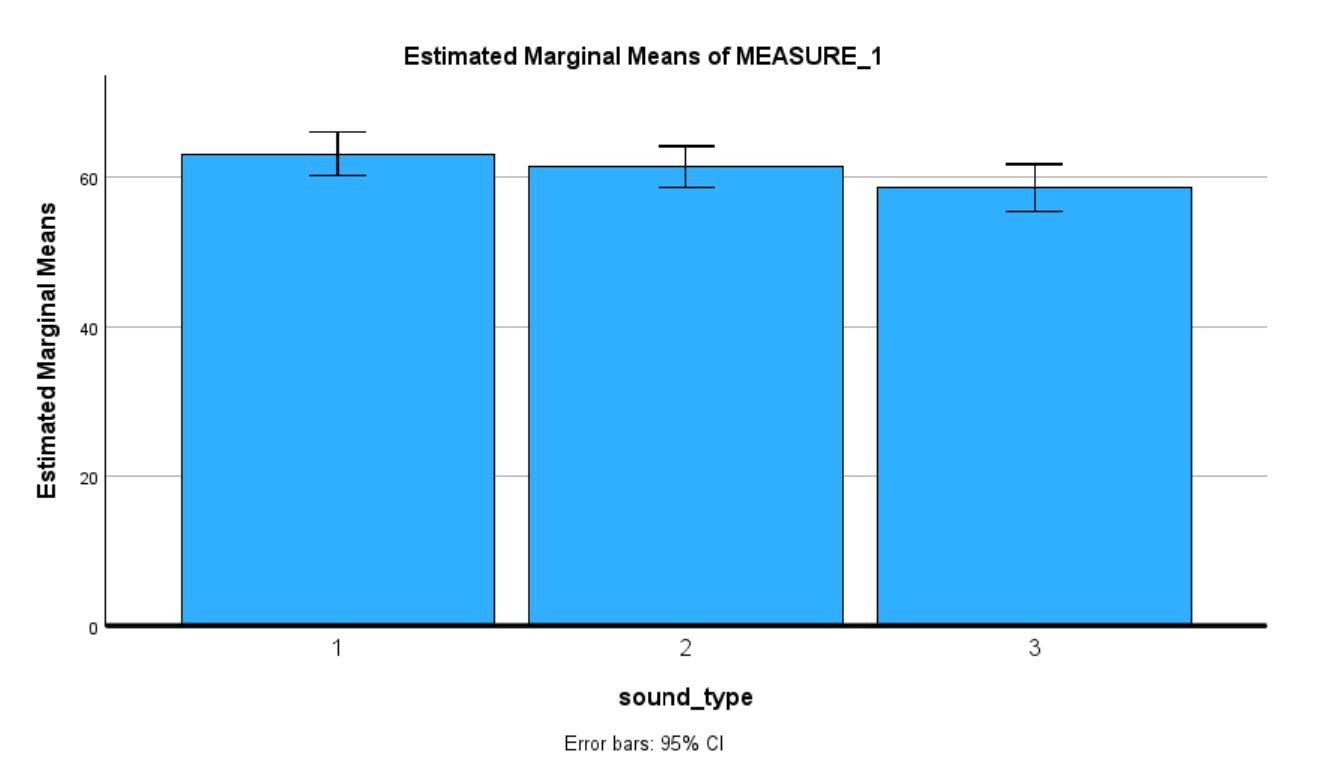
There was a significant difference in serial recall when silence was the background sound compared to speech (Mean difference=4.53, Bonferonni, p<0.05); serial recall accuracy was higher when silence was the background sound (Mean = 63.09; SD= 11.86) as compared to speech (Mean=58.56; SD=12.68).
There was not a significant difference in serial recall between silence and music or music and speech as the background sound.
Conclusion
The results confirm previous studies that irrelevant speech does have a disruptive effect on serial recall. However, a significant difference between music and silence was not found, suggesting that serial recall is not affected with music as a background sound and that speech does have a unique status in the irrelevant sound paradigm. This is inconsistent with previous studies where it was found that music regardless of preference impairs serial recall ability (Perham & Vizard, 2010; Bell et al, 2023) and that speech or non-speech sounds produced a similar disruptive effect on serial recall as compared to natural speech, albeit of a smaller magnitude (Tremblay et al, 2000). This is unlikely given that it challenges the fundamental notion of acoustical variation as the primary source of ISE. The findings prompt a re-examination of the conditions of this study where a supervised study done under consistent conditions should be favoured. If validated however, this challenges the assumption that music poses a hindrance, offering positive implications for students who study while listening to music. Additionally, it underscores the significance of speech as a disruptive sound in work environments, particularly where sequential recall is crucial.
Reference
1. Perham, N., & Vizard, J. (2011). Can preference for background music mediate the irrelevant sound effect? Applied Cognitive Psychology, 25(4), 625–631.
2. Tremblay, S., Nicholls, A. P., Alford, D., & Jones, D. M. (2000). The Irrelevant Sound Effect. Journal of Experimental Psychology. Learning, Memory, and Cognition, 26(6), 1750–1754.
3. Bell, R., Mieth, L., Röer, J. P., & Buchner, A. (2023). The reverse Mozart effect: music disrupts verbal working memory irrespective of whether you like it or not. Journal of Cognitive Psychology (Hove, England), ahead-of-print(ahead-of-print), 1–20.